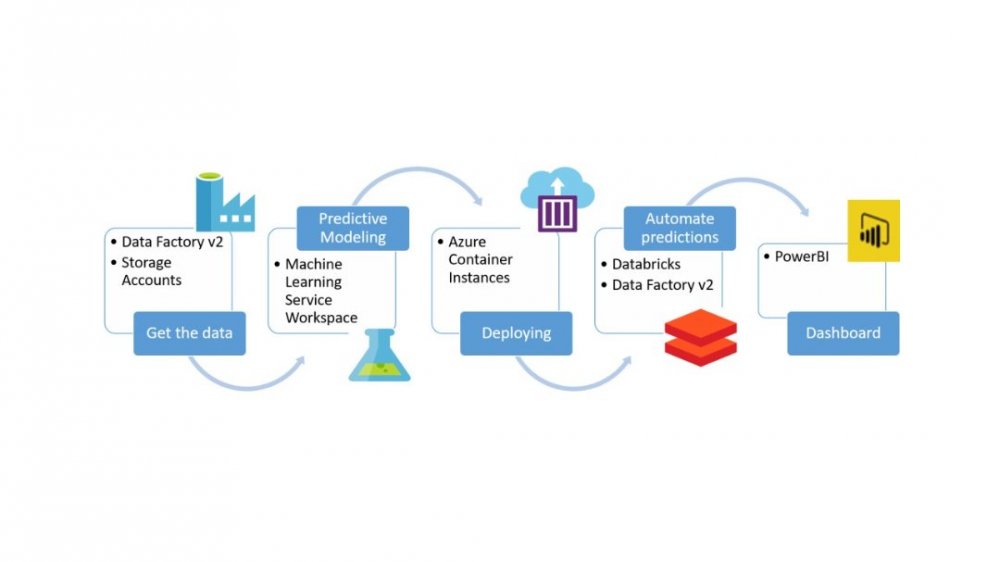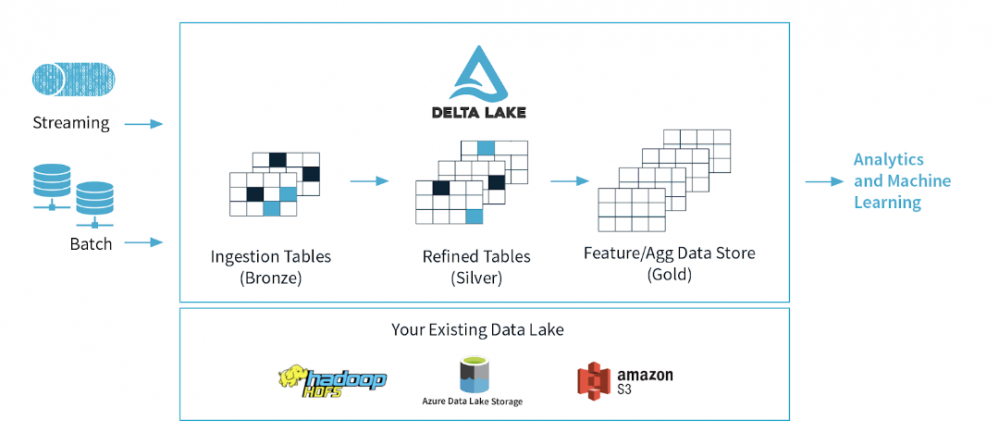
Den här artikeln introducerar Azure Data Lake Storage och Databricks Delta Lake. Ett lager för datalagring med öppen källkod från Apache Spark som ger tillförlitlighet och förbättrar prestanda till datasjöar.
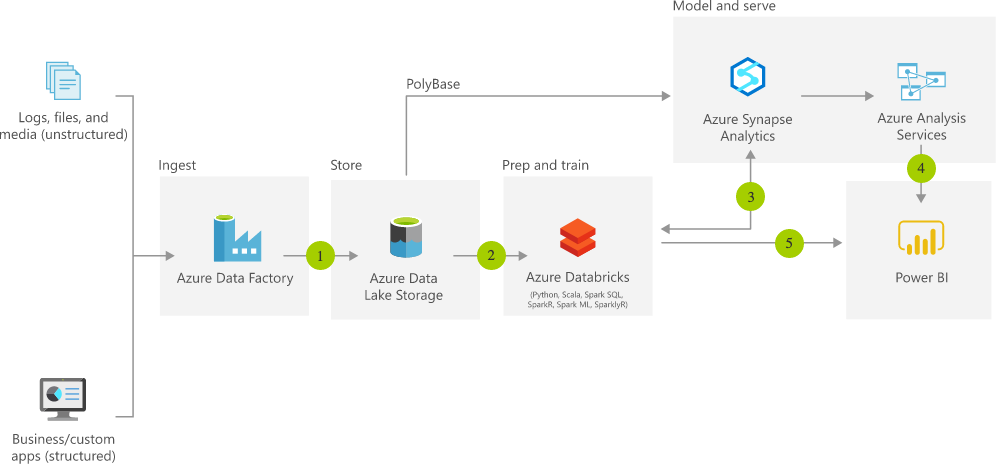
Vad är Azure Data Lake Gen2?
Data Lake Storage Gen2 gör Azure Storage till grunden för att bygga företagsdatasjöar på Azure. Data Lake Storage Gen2 är designad från början för att betjäna flera petabyte med information samtidigt som den upprätthåller hundratals gigabits genomströmning, och låter dig enkelt hantera enorma mängder data.
En grundläggande del av Data Lake Storage Gen2 är tillägget av en hierarkisk namnrymd till Blob-lagring. Den hierarkiska namnrymden organiserar objekt/filer i en hierarki av kataloger för effektiv dataåtkomst. En vanlig namnkonvention för objektlager använder snedstreck i namnet för att efterlikna en hierarkisk katalogstruktur. Åtgärder som att byta namn på eller ta bort en katalog blir enstaka atomära metadataoperationer på katalogen.
All rådata som kommer från olika källor kan lagras i en Azure Data Lake utan att fördefiniera ett schema för det. Detta är annorlunda jämfört med ett datalager där data först måste bearbetas och struktureras utifrån vissa affärsbehov innan de går in i datalagret. Azure Data Lake kan innehålla alla typer av data från många olika källor utan att behöva bearbeta den först.
Azure Data Lake kommer att lagra alla typer av data som kommer från olika källor på ett billigt, skalbart och lättbearbetat sätt.
Vad är Databricks Delta Lake
Azure Data Lake har vanligtvis flera datapipelines som läser och skriver data samtidigt. Det är svårt att behålla dataintegriteten på grund av hur stora datapipelines fungerar (distribuerade skrivningar som kan vara igång under lång tid). Delta lake är en ny Spark-funktion som släppts för att lösa exakt detta.
Delta lake är ett lagringslager med öppen källkod från Spark som körs ovanpå en Azure Data Lake. Dess kärnfunktioner ger tillförlitlighet till stora datasjöar genom att säkerställa dataintegritet med ACID-transaktioner samtidigt som de tillåter läsning och skrivning från/till samma katalog/tabell. ACID står för Atomicity, Consistency, Isolation and Durability.
- Atomicitet: Delta Lake kan garantera atomicitet genom att tillhandahålla en transaktionslogg där varje fullständigt genomförd operation registreras, och om operationen inte lyckades skulle den inte registreras. Den här egenskapen kan säkerställa att ingen data delvis skrivs vilket sedan kan resultera i inkonsekventa eller korrupta data.
- Konsistens: Med en serialiserbar isolering av skrivning är data tillgänglig för läsning och användaren kan se konsekventa data.
- Isolering: Delta Lake tillåter samtidiga skrivningar till tabellen vilket resulterar i en deltatabell på samma sätt som om alla skrivoperationer gjordes en efter en (isolerad).
- Hållbarhet: Att skriva data direkt till en disk gör data tillgänglig även i händelse av ett fel. Med denna Delta Lake tillfredsställer också hållbarhetsegenskapen.
Azure Databricks har integrerat Delta Lake med öppen källkod i sin hanterade Databricks-tjänst, vilket gör den direkt tillgänglig för sina användare.
Varför behöver vi Delta Lake?
Trots fördelarna med datasjöar, uppstår en mängd olika utmaningar med den ökade mängden data som lagras i en datasjö.
SYRA-transaktioner
Om en pipeline misslyckas under skrivning till en datasjö gör det att data delvis skrivs eller skadas vilket i hög grad påverkar datakvaliteten
Delta är ACID-kompatibelt vilket innebär att vi kan garantera att en skrivoperation antingen avslutas helt eller inte alls vilket undviker att skadad data skrivs
Enade batch- och streamkällor och sänkor
Utvecklare måste skriva affärslogik separat i en streaming- och batchpipeline med olika tekniker (t.ex. att använda Azure Data Factory för batch-källor och Stream Analytics för stream-källor). Dessutom finns det ingen möjlighet att ha samtidiga jobb att läsa och skriva från/till samma data.
Med Delta kan samma funktioner appliceras på både batch- och streamingdata och med alla förändringar i affärslogiken kan vi garantera att data är konsekventa i båda sänkorna. Delta tillåter också att läsa konsekvent data samtidigt som ny data tas in med hjälp av strukturerad streaming.
Schematillämpning & Schemautveckling
Inkommande data kan ändras över tiden. I en Data Lake kan detta resultera i datatypskompatibilitetsproblem, skadad data som kommer in i din datasjö etc.
Med Delta kan ett annat schema i inkommande data förhindras från att komma in i tabellen för att undvika att data skadas.
Om verkställighet inte behövs kan användare enkelt ändra schemat för data för att avsiktligt anpassa sig till data som förändras över tiden
Tidsresa
I en datasjö modifieras data ständigt så om en dataforskare vill reproducera ett experiment med samma parametrar från en vecka sedan skulle det inte vara möjligt om inte data kopieras flera gånger
Med Delta kan användare gå tillbaka till en äldre version av data för experimentreproduktion, åtgärda felaktiga uppdateringar/borttagningar eller andra transformationer som