
This article introduces Azure Data Lake Storage and Databricks Delta Lake. An open source data storage layer from Apache Spark that brings reliability and improve performance to data lakes.

What is Azure Data Lake Gen2?
Data Lake Storage Gen2 makes Azure Storage the foundation for building enterprise data lakes on Azure. Designed from the start to service multiple petabytes of information while sustaining hundreds of gigabits of throughput, Data Lake Storage Gen2 allows you to easily manage massive amounts of data.
A fundamental part of Data Lake Storage Gen2 is the addition of a hierarchical namespace to Blob storage. The hierarchical namespace organizes objects/files into a hierarchy of directories for efficient data access. A common object store naming convention uses slashes in the name to mimic a hierarchical directory structure. Operations such as renaming or deleting a directory, become single atomic metadata operations on the directory.
All the raw data coming from different sources can be stored in an Azure Data Lake without pre-defining a schema for it. This is different compared to a data warehouse where the data first must be processed and structured based on some business needs before entering the data warehouse. Azure Data Lake can contain all types of data from many different sources without any need to processing it first.
Azure Data Lake will store all types of data coming from different sources in a cheap, scalable and easy-to-process way.
What is Databricks Delta Lake
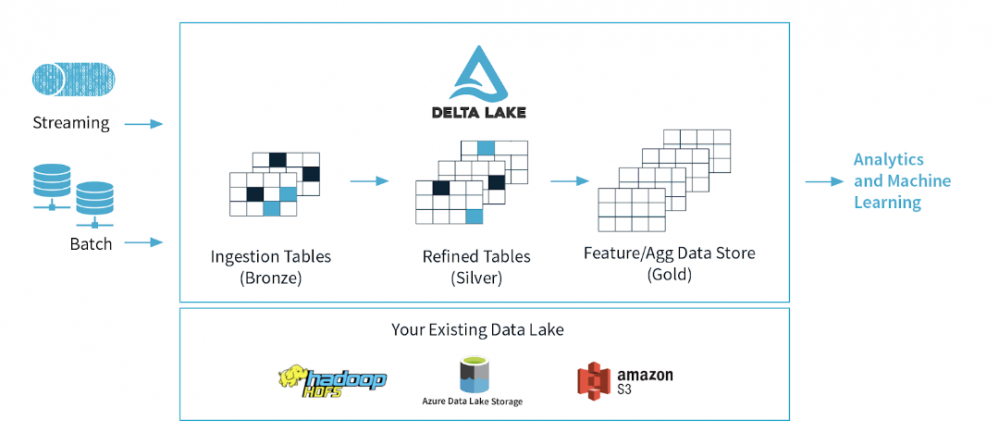
Azure Data Lake usually has multiple data pipelines reading and writing data concurrently. It’s hard to keep data integrity due to how big data pipelines work (distributed writes that can be running for a long time). Delta lake is a new Spark functionality released to solve exactly this.
Delta lake is an open-source storage layer from Spark which runs on top of an Azure Data Lake. Its core functionalities bring reliability to the big data lakes by ensuring data integrity with ACID transactions while at the same time, allowing reading and writing from/to same directory/table. ACID stands for Atomicity, Consistency, Isolation and Durability.
- Atomicity: Delta Lake can guarantee atomicity by providing a transaction log where every fully completed operation is recorded, and if the operation was not successful it would not be recorded. This property can ensure that no data is partially written which can then result in inconsistent or corrupted data.
- Consistency: With a serializable isolation of write, data is available for read and the user can see consistent data.
- Isolation: Delta Lake allows for concurrent writes to table resulting in a delta table same as if all the write operations were done one after another (isolated).
- Durability: Writing the data directly to a disk makes the data available even in case of a failure. With this Delta Lake also satisfies the durability property.
Azure Databricks has integrated the open-source Delta Lake into their managed Databricks service making it directly available to its users.
Why do we need Delta Lake?
Despite the pros of data lakes, a variety of challenges arises with the increased amount of data stored in one data lake.
ACID Transactions
If a pipeline fails while writing to a data lake it causes the data to be partially written or corrupted which highly affects the data quality
Delta is ACID compliant which means that we can guarantee that a write operation either finishes completely or not at all which avoids corrupted data to be written
Unified batch and stream sources and sinks
Developers need to write business logic separately into a streaming and batch pipeline using different technologies (e.g. Using Azure Data Factory for batch sources and Stream Analytics for stream sources). Additionally, there is no possibility to have concurrent jobs reading and writing from/to the same data.
With Delta, the same functions can be applied to both batch and streaming data and with any change in the business logic we can guarantee that the data is consistent in both sinks. Delta also allows to read consistent data while at the same time new data is being ingested using structured streaming.
Schema enforcement & Schema evolution
The Incoming data can change over time. In a Data Lake this can result in data type compatibility issues, corrupted data entering your data lake etc.
With Delta, a different schema in incoming data can be prevented from entering the table to avoid corrupting the data.
If enforcement isn’t needed, users can easily change the schema of the data to intentionally adapt to the data changing over time
Time travel
In a Data lake, data is constantly modified so if a data scientist wants to reproduce an experiment with the same parameters from a week ago it would not be possible unless data is copied multiple times
With Delta, users can go back to an older version of data for experiment reproduction, fixing wrong updates/deletes or other transformations that resulted in bad data, audit data etc.



